这篇博客主要从阿里巴巴的论文 “What’s the Story in EBS Glory: Evolutions and Lessons in Building Cloud Block Store” 来介绍云块存储。详细的内容可以参考 Fast2024 主页的演讲1。如果存在网络问题也可以从我本地连接下载,论文原文点击这里 ,PPT点击这里 。
阿里巴巴的云块存储从开始发展至今已经经过了多次迭代,从下面的时间线可以看出距离 2012 年的 EBS1 开始已经发展到了 EBSX 的版本。

BES1 #
在云计算的 IaaS 中,云厂商可以把计算资源和存储资源这些基础设施抽象成服务,对外以虚拟机的方式出售。云计算的客户只会感知到虚拟机提供的资源,但是在云计算厂商内部,虚拟机内的资源可以映射到不同的物理机上。计算和存储分离就是其中一种设计,通过将计算资源和存储资源放在不同的集群中,集群中间通过数据中心网络连接。这些设计也在微软的 Azure 和 Google 的数据中心中被采用。
块存储对外提供的是一种虚拟磁盘(Virtual Disk,VD),一台虚拟机可以挂载多个 VD。到目前我们云计算客户如果要使用存储资源,他们可以先购买不同容量的 VD,然后把 VD 挂载到自己的虚拟机中。事实上 EBS1 的设计也是如此,下图中计算集群中的 1 个 BlockClient 可以负责多个 VM,它们负责将 IO 请求转发到存储集群的 BlockServer 中。
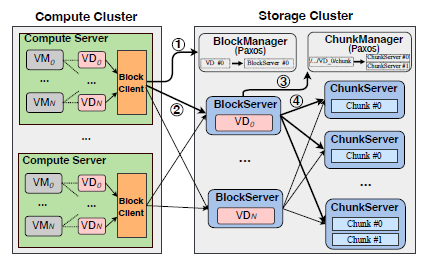
BlockServer 本身是无状态的,这就需要构建 BlockManager 集群来管理 VD 的元数据,包括容量,快照版本等等。另外 VD 的逻辑块地址(LBA)被划分成一个个 64M 的块(chunk)。ChunkServer 就是用来处理这一个个的 chunk。同样地,也需要有 ChunkManager 来管理 chunk 的元数据。
这时一个 IO 从计算集群的 VM 发过来,BlockClient 会先从 BlockManager 找到该 IO 应该发给哪个 BlockServer ,收到 ACK 之后发到对应的 BlockServer,然后 BlockServer 从 ChunkManager 查到该请求应该发给哪个 ChunkServer ,最后在一层层返回 ACK 给 BlockClient,这样就完成了一次 IO。
同样地,如果每次 IO 请求都需要从 Manage 集群查找对应的 Server 集群,将会带来很大的网络和时延上的消耗。所以在 BlockClient 和 BlockServer 中都会缓存这些元数据,这样就不用每次都去 Manage 集群中查询了。
以上是 EBS1 的主要内容,它虽然被部署到数百个集群中,但是仍然存在下面几个问题:
- 数据是 3 副本保存,会带来很大的写放大;
- 存储介质是 HDD,时延较高;
- 一个 VD 和一台 BlockServer 绑定,容易产生热点。
BES2 #
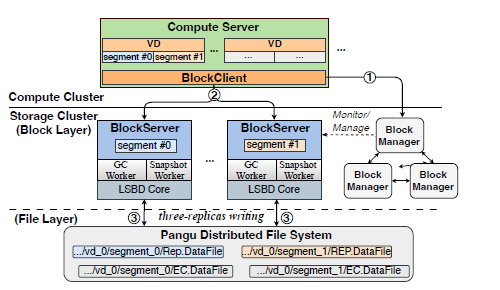
EBS2 的设计主要修复了上面的缺陷。从下图中可以看出新增了一层盘古分布式文件系统,它对外只提供了 append 写的原语,将 EBS1 的原地更新改为了追加写。因为只能 append,这就导致肯定会出现垃圾数据,从而需要有垃圾回收(GC)的流程。在 GC 的过程中通过校验码(EC)加压缩的方式来减少写放大,从原来的 3 倍减少到了 1.29 倍。存储介质也从 HDD 换成了 SSD,将平均时延提升到了 100us。
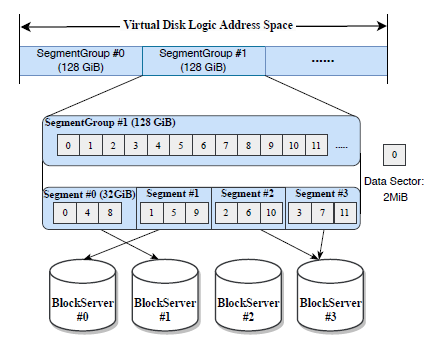
100us 最后的一个特性是将一个 VD 拆分成多个 128 GB 的段组,然后进一步将每个段组拆分成多个 32 GB 的段,这有助于缓解热点的问题。
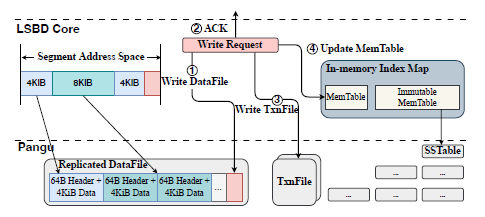
因为 EBS2 采用了 append only 的方式,所以引入了日志结构的块设备(Log-structured Block Device)来加快读的索引。它本质上是一个日志结构合并树(LSM Tree),记录 VD 的 LBA 和对应到 DataFile,offset 和 length 的映射。下面的图片展示了 EBS2 写操作的流程,首先是按照 4K 数据 + 64B 元数据的形式写 DataFile,然后返回写成功 ack,第 3 步是将 VD 的 LBA 和对应到 DataFile 的映射记录在 TxnFile 中,EBS2 可以通过读取 TxnFile 的映射来恢复内存中的索引映射,而不用扫描 DataFile 中的数据块尾部。最后是在段迁移的时候将映射更新到 LSM 树中。需要注意的是 DataFile ,TxnFile 和 LSM Tree 中的 SSTables 都是盘古文件。
除了上面的变化以外, EBS2 在网络和快照上也产生了一些变化。网络上用用户态的 TCP 替换了 EBS1 的内核态 TCP,并且使用 2 * 25 Gbps 的 RDMA 网络,以满足严格的 SLA 要求。但是网络的变化只针对数据面,控制面(如 BlockManage 和 BlockServer 之间的 RPC) 之间的网络还是用内核态 TCP。在 EBS2 中创建快照可以通过异步更新的方式。BlockManage 只需要记录一个时间戳,并要求 BlockServer 中的 Snapshot Worker 模块上传从上次快照时间戳到最新时间戳之间的数据,使得 EBS2 中为 20GB 数据生成快照只需要 30S,而在 EBS1 中平均需要 33 分钟。
EBS2 也带来了一些局限性,
- 它将流量放大从 EBS1 的 3 变成了 4.69,包括前台写的 3 副本,加后台 GC 读的 1,和 EC/压缩之后的 0.69,这导致最后只有 15.5% 的网络带宽是用来处理 VD 的请求。
- EC 的引入为了实现高压缩和编码效率,要求数据块大小至少为 16KB, 然而实际中近 70% 的请求小于 16 KB.
EBS3 #
EBS3 通过引入融合写引擎(Fusion Write Engine ,FWE)来合并小块写的请求,并且采用 FPGA 来卸载压缩计算,从而实现在线 EC 和压缩。
在下图中,步骤 1 将不同 VD 的不同段写入 FWE,FWE 随后(写入数据达到默认 16KB)将这些写入数据组合成数据块,然后将其发送到基于 FPGA 的加速器中进行数据压缩(步骤 2),然后调用盘古的 API 将压缩后的数据作为带 EC (EC(4, 2)的日志文件进行持久化,写入到 JournalFile,即步骤 3;第 4 步就可以返回写成功的 ACK 消息;随后, EBS3 将未压缩的数据保存到 BlockServer 的内存中,按照一个一个的 segment 进行保存(步骤 5),当 SegmentCache 中的数据达到阈值(默认为 512KB)的时候,再通过 CPU 压缩数据,将其追加到 EC(8, 3) 的数据文件中,并且更新 TxnFile 和内存索引映射。
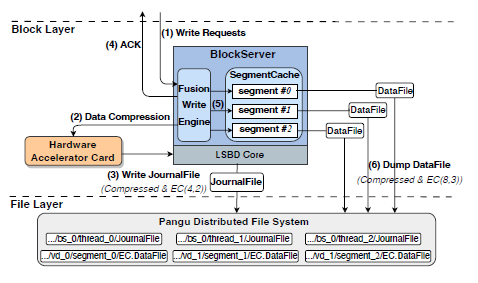
在 EBS3 的架构之下,对于读的请求首先在 SegmentCache 中查询最新数据。如果找不到,进一步读取内存中的 LSM Tree。因为写到 JournalFile 中的数据是经过 EC 和压缩的,并且来自不同的 VD 的不同段,直接从 JournalFile 中获取数据可能会导致严重的读放大。因此,JournalFile 在运行时仅用于写入,只有在故障时才用于读取,来恢复尚未转储的数据。
在 FWE 中,因为将所有的小块写都合并起来会导致小块写的时延变大,所以对于小块写并不频繁的集群(例如平均只有 3.72% 的 IO 是 4KB 写入),并不会合并 4KB 写,而是直接采用传统的三副本复制。
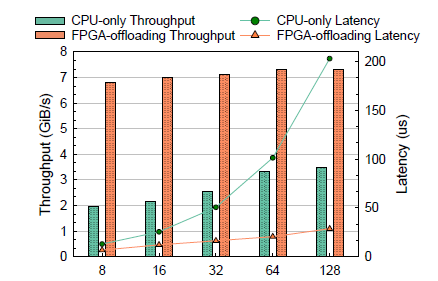
下图展示了 FPGA 和 CPU 压缩在性能和吞吐量上的对比。 在不同块大小的对比之下,FPGA 的时延分布在 29 - 65 us 之间。特别低,在数据块大小是 16KB 的时候,FPGA 的时延比 CPU 降低了 78%。除此以外,FPGA 的最大吞吐量是 7.3 GiB/S,而 CPU 只有 3.5 GiB/s.
EBSX #
下图是不同版本的 EBS 在 8KB 块大小情况下统计的 IO 路径上的时延,数据来自于前 10% 最繁忙的生产集群。首先可以观察到 2 跳网络(图中橙色和粉色)和磁盘IO(图中为黄色)占据了总时延的很大部分。另外由于前端的 EC 和压缩, EBS3 在 BlockServer 侧的时延要比 EBS2 更高,但是减少的数据量使得其在第 2 跳网络中传输的时间更少,最终 EBS2 和 EBS3 的总时延相似。
另外读写操作之间的主要区别在于盘 IO 时延,EBS2 使用的是 TLC-based SSDs,EBS3 使用的是 QLC-based SSDs,这导致 EBS3 在盘 IO 的时延上要更大一点。为了进一步改善硬件上带来的时延消耗,存储团队构建了 EBSX,目标是时延敏感的场景。EBSX 在 BlockServer 中安装了持久化内存(PMem),并直接将数据以 3 副本的形式存储在 PMem 中。因为减少了一跳网络,并通过 PMem 极大加快了盘 IO,最终下图中 EBSX 在读写操作上可以达到 30us 的时延。需要注意的是,巍峨空间效率,PMem 中的数据最终还是会被刷到盘古中,图中的数据是基于缓存命中的性能表现。

上图 (b)中展示了 EBS3 99.999% 百分位延迟的拆解,团队收集了数百万个慢 IO,并计算了平均时延。最后观察到 BlockServer 占据了尾部时延的大部分,而不是硬件原因。最后分析表明,由于前台 IO 和后台任务用的是同一个线程,会发生线程的抢占。为了解决这个问题,将 IO 流量和其他任务进行了隔离,并在独立线程上执行,通过这些改进, EBS3 的 99.999% 写操作时延已经减少至 1ms,读操作减少至 2.5 ms。
-
https://www.usenix.org/conference/fast24/presentation/zhang-weidong ↩︎
Last modified on 2024-10-05