深度学习中训练参数的规模在不断变大,数据量也在不断变大,这就导致一块 GPU 卡很难在短时间内使得模型收敛。所以人们尝试采用多块 GPU 卡进行训练,由于在训练时通过一个一个的 batch,假如一个 batch 是 10 条训练数据,那可以尝试将这 10 条训练数据分到 2 块 GPU 上进行训练,每块 GPU 上训练 5 条数据。最后再把各自训练的梯度传回给 CPU,由 CPU 对结果进行加和,根据学习率和优化算法对进行梯度下降,然后再把新的代训参数分别传回给两块 GPU,再进行下一个 batch 的训练。这种训练的方式称之为数据并行。如果采用数据并行的方式,理想情况下 2 块 GPU 芯片可以使得训练的时间减半。但是一台服务器上可以插的 GPU 个数总是有限的,所以人们提出了采用多台服务器组成分布式系统来进行训练。
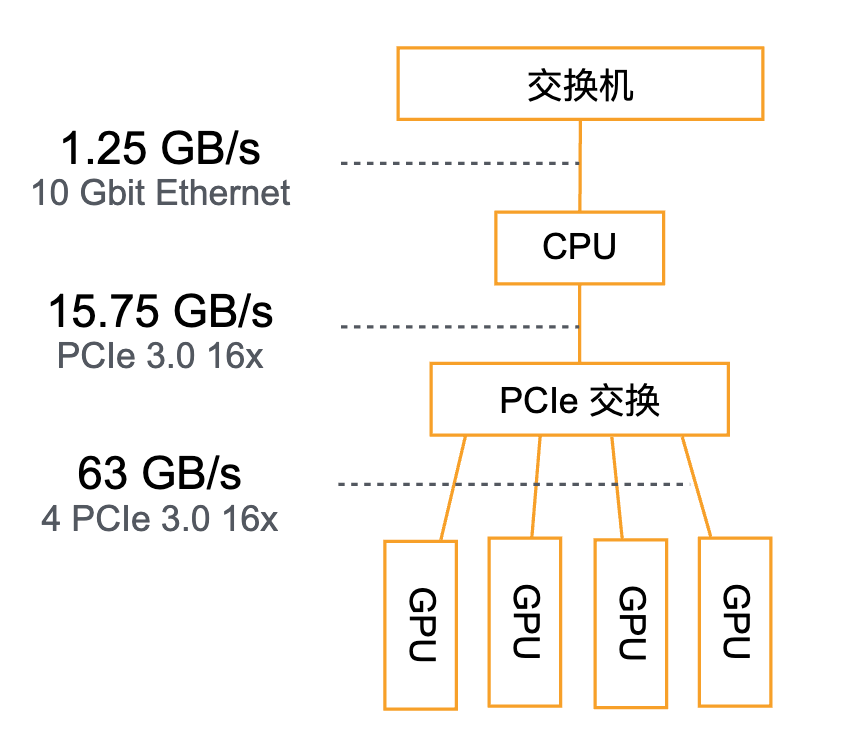
在分布式系统训练深度学习的时候往往计算速率是足够快的,而数据传输会成为瓶颈。下图描述了分布式系统中各个模块可以传输的带宽。最下面是各个 GPU 内存之间的数据传递,它们之间通过 PCIe 总线传递数据,传输带宽可以达到 63GB/s。中间是 CPU 和 GPU 之间的数据传递,它们之间就要小很多,一般来讲就是 16GB/s。最后就是不同服务器之间会通过交换机进行数据传递,这之间的数据传输带宽就更小,假如是 10GE 的交换机,也只能有 1.25GB 的传输带宽。从上面的数据可以看出,进行多 GPU 数据训练的核心就是尽量减少数据跨 CPU 和 GPU,以及跨不同的服务器。
在参数服务器中往往有下面几种角色,下图是 Task Scheduler 的功能,它负责把数据 load 到不同的 worker 上,并且迭代 T 次,进行数据的训练。

然后是 worker,它实现了参数读取的功能,能够把它需要的参数从 server 读到自己的节点。因为随着模型不断变大,可能没有办法的全量的模型都加载到显卡内存,LOADDATA() 就实现了只把自己需要的这部分参数读取过来。
Worker 同时还实现了 WORKERITERATE(t),它的作用就是对数据进行迭代,计算出梯度,然后发给 server,并且从 server 那里拿到下一轮需要迭代的参数。

Servers 实现了 SERVERITERATE(t),可以把第 t 时刻 worker 传过来的梯度相加,并且根据优化函数沿着梯度的反方向得到下一轮要训练的参数 W。
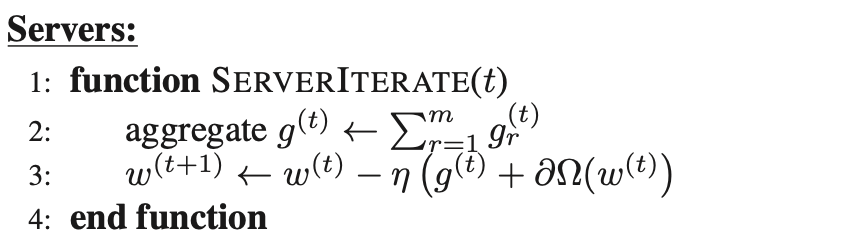
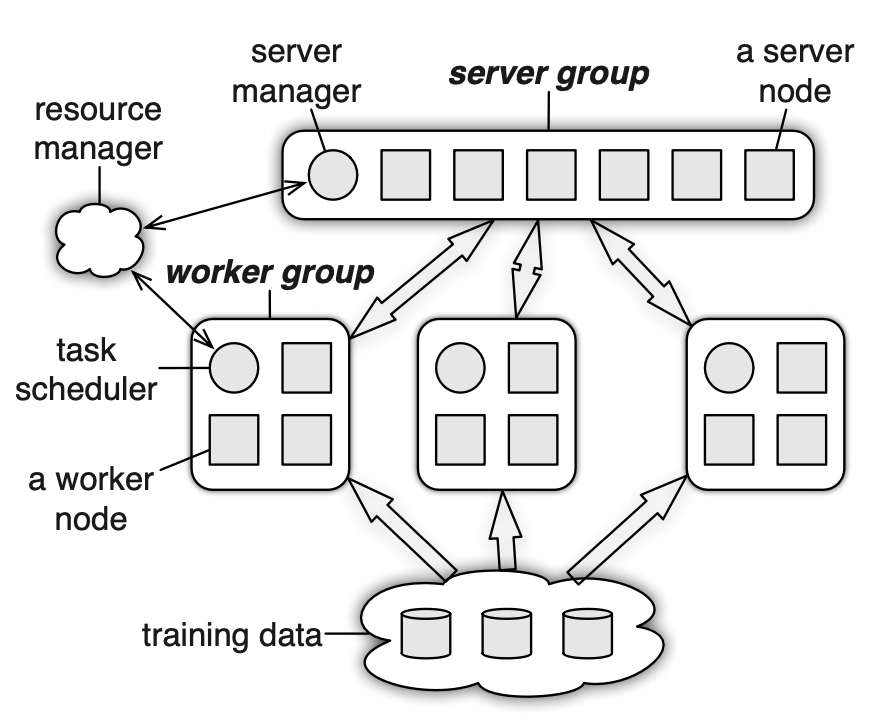
下图是参数服务器这篇论文里主要的一个架构图。最左边有一个 resource manager 的角色,它的作用是管理这个分布式系统的服务器资源,可以随时进行扩减容。最上面是一个 server group,它里面有一个 server manager,作用是和 resource manager 进行通信,并且分配了这个组里每台服务器需要管理的参数。里面画了 6 个方块,表示有 6 个 server 的进程,这是因为在参数特别大的时候一台服务器没有办法把参数全部存到内存总,需要拆分成很多段,每台服务器存储其中的一段。Server 里存储的参数是 <key, value> 的结构,它的 key 是指待训练的参数下标,value 可以是具体的参数 w,也可以是一整个层的参数向量。
接下来是一个 worker group,它们是真正进程计算任务的节点,每个节点都是无状态的。在 worker group 里面有一个 Task Scheduler,它也是和 resource manager 进行通信的,具体作用在前面的算法中也提到了。方块是真正进行计算的节点,它会和 server 以及最下层存储数据的服务器进行通信,每次拿到最新的待训练的参数,并且进行训练。和 server 通信的接口被抽象为 push/pull,如果每次都传 <key, value> 会导致 key 占比较大的带宽,所以它允许在传惨的时候一次传一批过去,这样只需要定义好 range 的长度,就可以找到是一个段的 w。
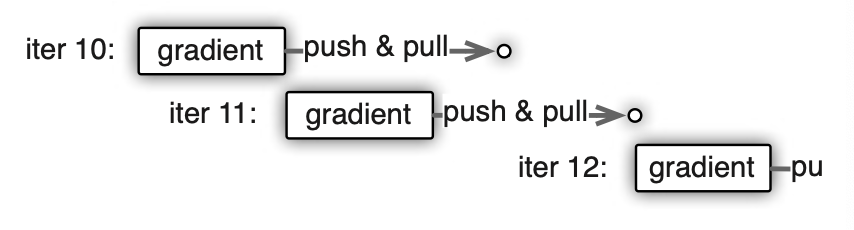
特别地,在任务训练的过程中可能涉及到一些同步的异步的任务。在一个 work 把计算完的梯度传给 sever 之后它需要向 server 拿到下一轮待训练的参数,但是 server 可能正在等待其他的 worker 把自己的梯度计算完成回传,这个时候是没有办法拿到最新参数的。下图中迭代 11 就是在迭代 10 发送完 push&pull 请求之后就直接开始了下一迭代梯度的计算,这样可能会使得模型收敛变慢,但是不会让 cpu 等待在那里。迭代 12 则是添加了一个依赖,必须等迭代 10 的任务完全完成,才会开始下一迭代的计算。
系统在一致性协议上采用了一个 Vector Clock 的设计。对于 server 节点来讲,每个 worker 可能都处在不同的版本,为了保证能够管理到每个版本, server 必须把自己的参数复制 worker 个数次,这样带来的开销就会很大。但是因为每次传输的过程中都是传的 range key,一次传输可能是某一段或者某一层的权重数据,这样就会很大程度上降低 server 存储的压力。
具体权重在不同 server 上的存储是采用了下面一致性 hash 的方式。把所有权重打散到一个哈希环上,每个服务器存储其中的一段,并且会存储往后连续的两段作为备份。下图中 S1 - S2 这一段是由 server 1 维护,同时它还保存了 S2 - S4 作为数据的备份。在实际训练中备份参数的更新是实时的,也就是说每次 server 都会更新自己本地节点,同时也会把自己的备份的节点更新才会返回更新成功。这种操作会增大交互的时延,但是目前的深度学习训练任务中时延并不是瓶颈。
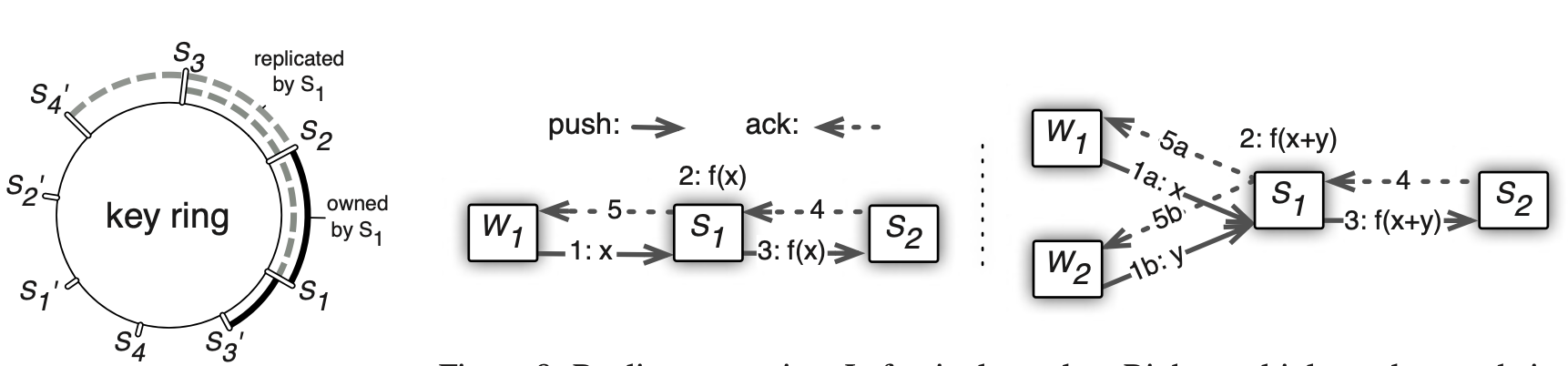
如果要扩减容,只需要在哈希环中插入或者合并一段就可以。
参考:
- https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-li_mu.pdf
Last modified on 2025-08-16