背景 #
Resnet 是 2016 年提出来的,当时深的神经网络都比较难以训练,所以作者提出了一种基于残差的神经网络。在 imageNet 的数据集上采用了 152 层的神经网络,并且拿下了当年竞赛的第一名。同时值得一提的是这篇论文截止目前已经有 27万+ 的引用。

假设在一个深度神经网络的训练中模型已经能很好地拟合训练数据,在这个过程中再加入新的层,理想的情况应该是这个新加入层的参数可能被训练成一些对实际结果影响不大的值,这样可以保证总体上训练的结果不变,但是实际上很难做到这一点。Resnet 的核心思想如下图,假设之前某一层的输出 x 作为新加入层的输入,新加入层的参数训练效果可以用 F(x) 来表示。作者在这一层输出的基础上同时还施加了上一层的输出 x,使得新加入层的训练效果变成了 F(x) + x,把新加入的 x 就称为残差。
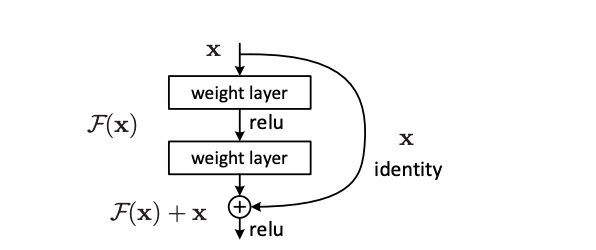
因为是在 F(x) 的基础上直接加了 x,它们本身的维度可能并不一致。所以作者也给出了集中解决方案,一种是用 0 去做填充;还有就是采用 1 * 1 的卷积核,使得输出通道可以是输入通道的 2 倍,同时再用一个长度为 2 的步幅,使得最后通道,宽,高都能够对应上。
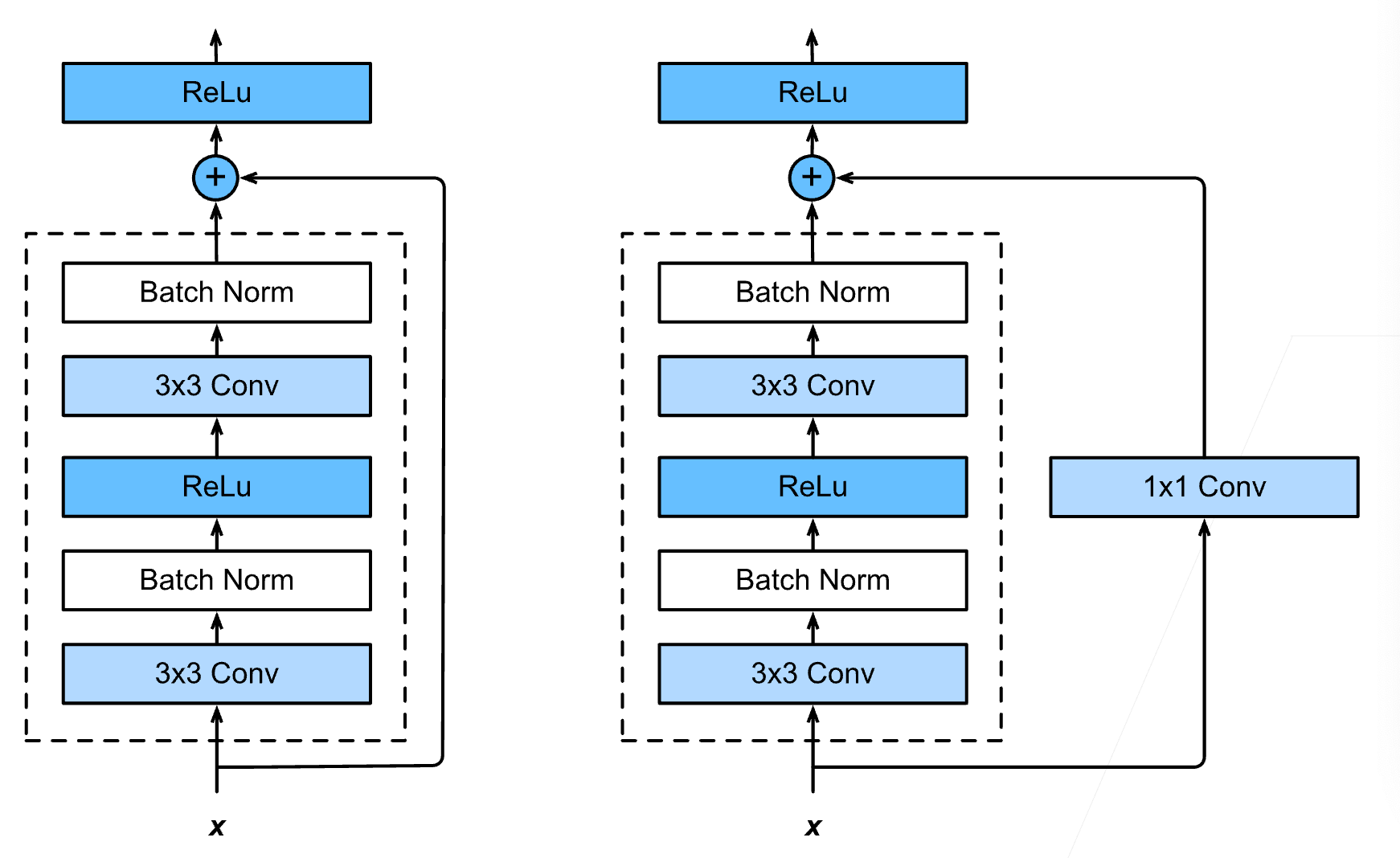
更具体的细节在下面这张图, Resnet 借鉴了 VGG 的思想,每一个 Resnet 的块包含了两个 3 * 3 的卷积神经网络,下图右边 1 * 1 卷机层的作用就是通过调整通道,使得最后可以加到一起。
下面给出 resent 的代码实现。
Resnet 代码实现 #
首先定义一个残差的块。构造函数里加了一个参数来表示是否要用 1 * 1 的卷机层,和上图对应。在卷机层中设置 kernel 为 3,padding 为 1,可以保证输出的高,宽和输入时一样。strides 参数通常用在需要对输出通道数增加的时候,需要要使得输出通道数加倍,可以把 strides 设为 2,这样可以让输出的宽高减半。
import torch
from torch import nn
from torch.nn import functional as F
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return self.relu(Y)
然后采用上面的残差块构造完整的 resnet,
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
Fashion mnist 数据集图片的格式是 [1, 64, 64],是一个单通道,宽高都是 64 的图片(对于这个数据集更详细的介绍可以点击这里 ),在 resnet 网络中的训练过程可以看到每一层形状的变化。
X = torch.rand(size=(1, 1, 64, 64))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
显示的效果如下图,可以看到第一层宽高都变为原来的 1/4 了,这是因为经过了一层池化层,并且 stride 是 2.后面几层都是通道数加倍,宽高减半

最后采用 fashion mist 实际训练一下 resent 模型,训练效果如下图,
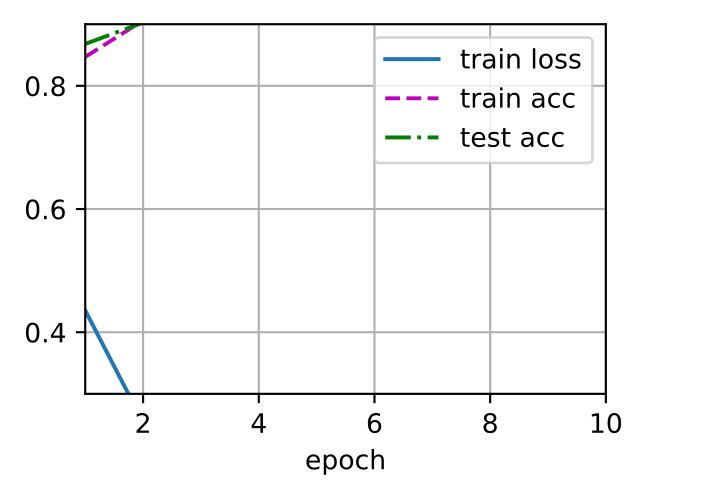
可以看到在这个小的数据集上测试精度已经接近 100% 了,然后再抽部分数据进行预测,依然都能准确分类。

Last modified on 2025-07-27