InnoDB存储 #
InnoDB 存储引擎是 MySQL 中最常用的存储引擎之一,其存储结构是一个复杂的组合,充分利用了磁盘、内存和日志来提供高性能、事务支持和数据一致性。它的存储结构包括以下几个重要的组成部分:
表空间(Tablespaces): InnoDB 存储引擎的数据存储是基于表空间的,每个表都有自己的表空间,包括系统表空间和用户表空间。系统表空间包含了数据字典等系统信息,而用户表空间包含了用户创建的表和索引数据。表空间实际上由一个或多个数据文件组成,这些数据文件是磁盘上的物理文件,用于存储表的数据和索引。InnoDB 存储引擎的数据文件通常以 .ibd 扩展名结尾。
表空间由三个段的内容组成Leaf node segment,Non-Leaf node segment 和 Rollback segment
- Leaf node segment:主要存的是表里的记录
- Non-Leaf node segment:主要存主键索引和从索引
- Rollback segment:存储事务回滚的数据
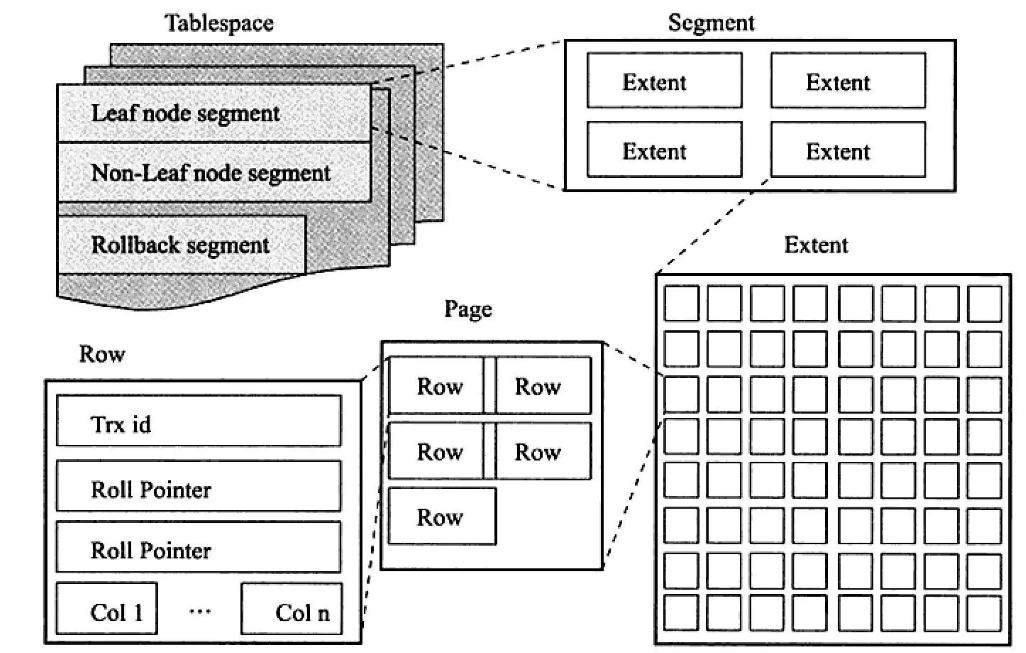
我们主要介绍段的概念。正如上面列举的那样,段里面主要存储了数据,那它就需要支持我们去动态扩增,而扩增的单位就是 Extend,默认的大小是 1M。一个 Extend 里有 64 个 Page,所以 1 个 Page 的大小为 16K(一次从磁盘读进来的数据就是一页 16 K)。Page 里则是存储着真实的记录,但是由于记录大小本身不固定,所以 1 个 Page 里有多少条记录也是不确定的。
页是由下图所示的这几部分组成的,数据主要存储在 User Records 里, User Records 里存储的数据可能是按照主键由小到大排列,也可能是无序的插入,这个和具体的操作相关。如果发生了删除和重新插入这些操作,内部的存储就会更加无序。
我们可以通过 Page Directory 快速找到具体某一行的记录,Page Directory 有序排列了主键,可以通过二分法快速查找。

B+ 树索引结构 #
InnoDB 存储引擎使用 B+ 树索引结构来管理数据,包括聚集索引和辅助索引。聚集索引是表的主键索引,决定了数据在磁盘上的物理存储顺序,而辅助索引用于加速查询。
B+树中叶子节点是以 Page 为单位进行存储的。并且两个页之间的主键是有序的。既然是树结构存储,那就必然需要处理增删改查这些场景,尤其是对于插入数据时需要对页进行拆分的情况,如果插入操作导致数据页的分裂,InnoDB 还需要更新父节点的索引,以反映分裂操作的结果。 为了确保数据的持久性,InnoDB 会将插入操作写入重做日志(redo log)。这是为了在发生崩溃或故障时能够恢复插入操作。写入重做日志是一个必要的步骤,以保证事务的原子性和持久性。为了使分页的代价降到最低,一般来说主键都是自增的,不允许随意去定义。
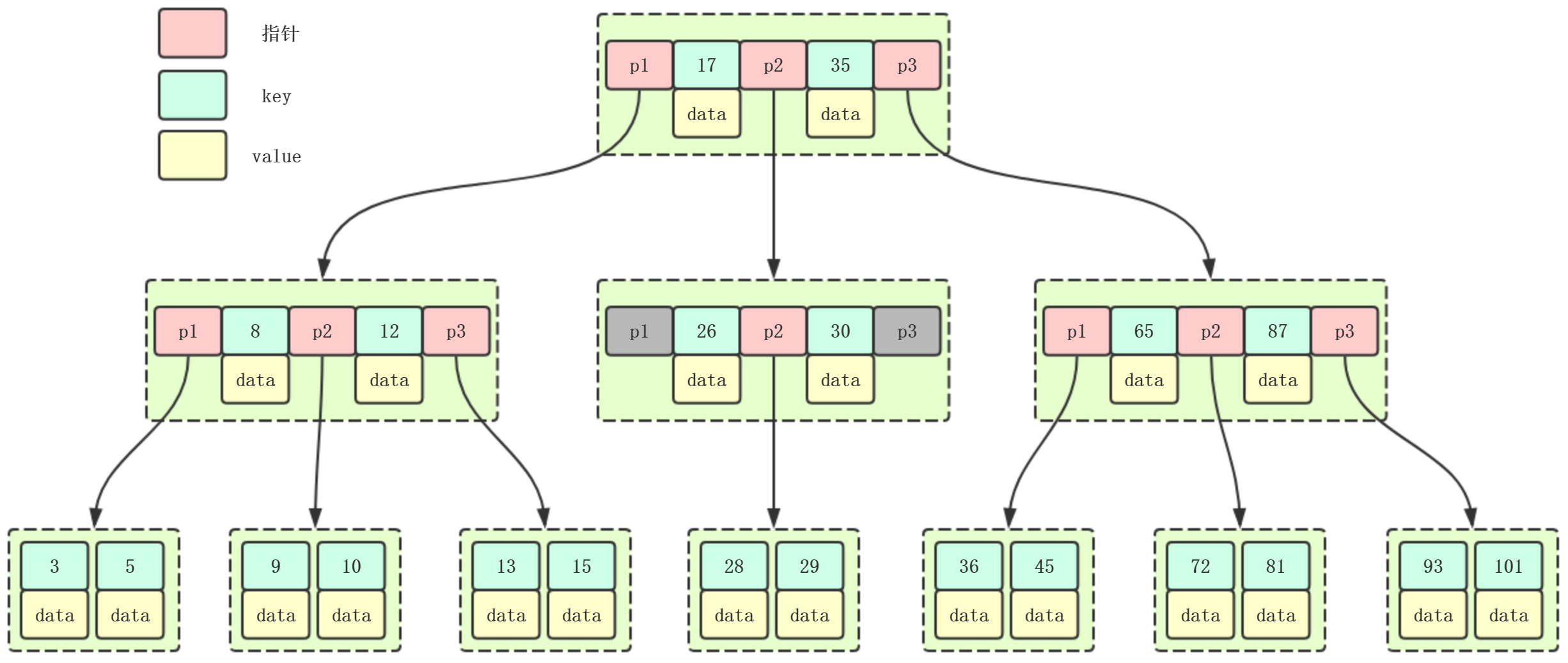
执行删除操作时,会将数据标记为删除,并将删除操作记录到重做日志中。在一些情况下,删除操作可能导致数据页的合并。
我们刚刚谈的都是主键索引,对于辅助索引来说它仍然使用B+树,但是它的值是 key,也就是说我们需要先从辅助索引里找到 key,再通过主键索引去查具体的记录,外键一般都需要建立辅助索引。假设现在我们有一个需求,需要查找哪些网页中出现了我们需要的关键字,这种情况下我们就必须要建索引,不然就是一趟全量查找。但是如果建辅助索引,这个操作耗时仍然很恐怖,所以这种场景可以考虑使用 ES,ES 最著名的就是它的“倒排索引”,会把关键字作为键,主键作为值来建索引。
InnoDB 使用缓冲池来缓存表和索引的数据,以加速读取操作。缓冲池是内存中的一块区域,用于存储最近访问的数据页。这样,在查询时,如果数据页在缓冲池中,则可以快速获取,而不必从磁盘读取。
事务 #
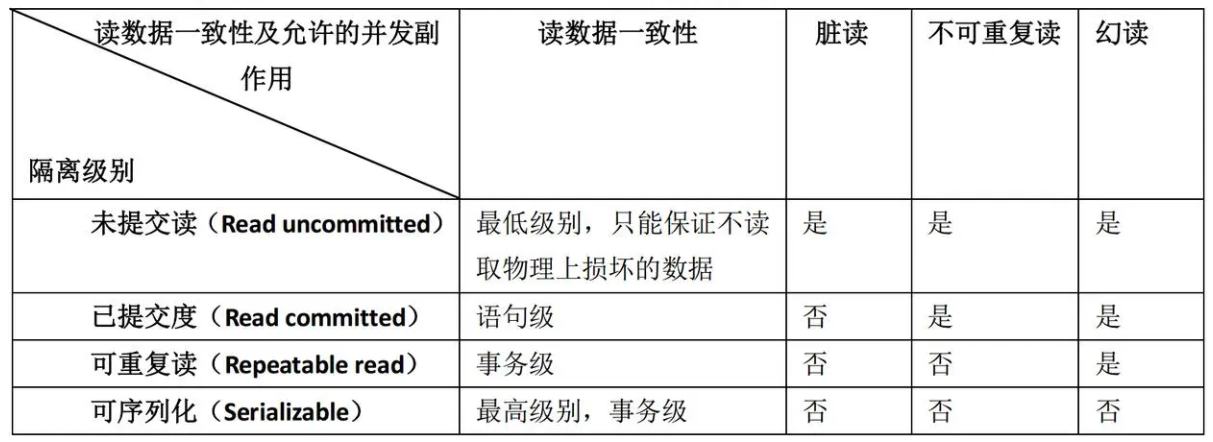
事务是数据库里必不可少的一个概念,它也是并发控制的基本单位,基本在大大小小的考试面试中都会涉及到它的 ACID,这个没什么好说的。我们重点来了解一下事务隔离性中的隔离级别。所谓隔离性就是一个事务的执行不能被其他事务干扰。在介绍隔离级别之前我们先来了解一下脏读,不可重复读和幻读的概念。为了方便描述,我们假设现在有一个场景:大家购买从北京到上海的车票(假设都存在一张表里),发现就一趟车(表的记录数为1),车票余额的记录初始为100(这条记录里余额这个属性的值为100),假设买车票的时候需要做这几件事,第一件是读这条记录(READ 操作)把余额减1(WRITE 操作),然后需要等待用户付款,在付账成功之后再读一次这条记录确认修改成功(READ 操作),最后 commit 这个事务。整个过程需要两次读操作和一次写操作。
- 脏读:读取了其他事务未提交的数据。对于上面提到的场景,可能有一个人开始订票的时候就开启了一个事务,先将记录减 1 变成 99(执行了 WRITE 操作),然后是调用第三方接口去付款,但是如果中途这个人不想继续订票了,那事务就会 Rollback,最终数据库的余额都是100。可是在事务开始到 Rollback 之间如果别的事务也查询(READ 操作)这个值就会查到 99,这个读到的数据就是“脏数据”。
- 不可重复读:同样是上面的例子,假如我们解决了脏读的问题,现在有两个人开始订票,并且同时开启事务,他们读到的数据都是 100,在这个过程中 A 最终付款成功 commit 事务。但是B中间延迟了很久最终放弃了付款,可是在第二次读的过程中发现记录数还是变成了 99,B 在一个事务中不能重复读。B 并没有修改数据但是数据发生了变化会让 B 感觉不舒服,因为我们需要把每个事务隔离开,每个事务各自之间是不感知其他事务修改的。
- 幻读:假如我们也解决了不可重复读的问题,这样我们是解决了读写一条记录的问题,但是我们没有解决在一个事务里会往表里面插入删除数据的场景。比如一开始大家发现就一趟车,记录数是 1,余额是 100,然后用户开启事务买票,在这个事务中间可能有查询了一次有几趟车,结果发现发现记录数变成了2,又出现了另一趟车,这就出现了幻读的问题。
上面我们都是假设这几种问题都被解决了,那么在实际中要怎么解决这三种问题呢?首先我们同样需要了解两种锁,共享锁和排他锁。共享锁是当一个事务在执行 READ 操作的时候会加的锁,加了之后这个事务和别的事务就都不能写但可以读。同样的,别的事务可以在共享锁的基础上再加共享锁,它们是兼容的。排他锁则是在执行 WRITE 操作的时候加的锁,加完之后这条记录就只能由该事务处理,别的事务就不能读写了,在加了排他锁之后就不允许其他事务再加共享锁了。这三个问题就是通过加这两种锁来实现的。
- 脏读:解决脏读问题就是对记录加共享锁和排他锁,排他锁直到事务结束释放,共享锁读之前加,读完就释放;因为加了排他锁之后不允许其他事务加共享锁,所以其他事务会被阻塞住,直到拿了排他锁的事务 commit 或者 Rollback。
- 不可重复读:对记录加共享锁和排他锁,和解决脏读问题的区别在于共享锁读在之前加,直到事务结束再释放;
- 幻读:对整张表加共享锁。
四种隔离级别Read Uncommitted,Read Committed,Repeatable Read 和 Serializable 就是分别解决上面问题的一种或者几种,如下表所示:
MySQL 一般用的隔离级别是 Repeatable Read, Oracle 默认是 Read Committed,并且 MySQL 采用了多版本并发控制( MVCC) 的实现机制来实现 Repeatable Read,按照上面加锁的实现,当一个事务加了排他锁之后别的事务就不能去读了,它会被阻塞住,但是 MVCC 会让这个事务读到它第一次读的那个值,同样保证前后读的值是一致的。
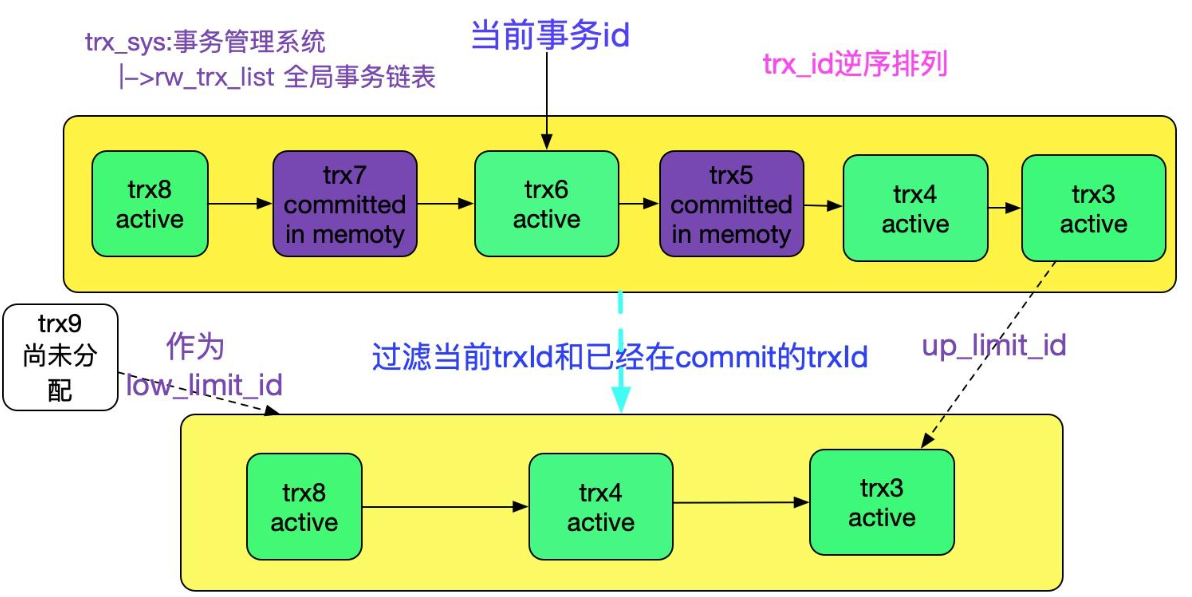
MVCC 是通过快照的方式来实现 Repeatable Read 的,当有事务写这条数据的时候会把新数据持久化到表里,把原来的数据写到 undo log。当一个事务需要读取数据时,它会查看 Undo Log 中的记录来获取数据的一个一致性快照,以确保读操作不受正在进行的写操作的影响。 MVCC 通过下面的这些 id 值来产生不同事务的快照:
- creator_trx_id:生成 ReadView 的事务 id
- trx_ids: 当前活跃的事务id,已经开始没有提交的事务 id
- low_limit_id: 下一个将被分配的事务id(事务 id 是递增的)
- up_limit_id: trx_ids 中最小的事务id
在查询的过程中先查看 creator_trx_id,如果和查询的事务 id 一致,说明是自己创建的,则数据可见;如果查询的事务 id (trx_ids)>= low_limit_id,说明 low_limit_id 实在查询事务之后开始的,则不可见;如果 trx_ids < up_limit_id,则可见;如果 up_limit_id <= trx_ids < low_limit_id,只要事务时活跃的,则不可见,否则可见。
日志文件 #
在数据库中日志属于一等公民,需要保证数据的恢复机制,所以需要用到日志文件(Log Files) ,InnoDB 使用事务日志来记录已提交的事务,以确保数据的一致性和持久性。除了我们上面提到的 undo log 用于处理并发以外 MySQL 还有重做日志文件(redo log)和慢查询日志文件(slow query log)用来应对其他的业务场景。
-
重做日志文件(Redo Log):InnoDB 存储引擎有两个重做日志文件,通常命名为
ib_logfile0和ib_logfile1,它们用于记录事务的修改操作。它们的大小和数量由配置参数 innodb_log_file_size 和 innodb_log_files_in_group 决定。数据修改操作首先被写入 Redo Log,然后才被写入磁盘,这些日志文件允许数据库在崩溃后恢复到一致的状态。当数据库需要恢复到正常状态时,通过重演 Redo Log 中的操作,可以更快速地将数据库恢复到崩溃前的状态。 -
慢查询日志文件(Slow Query Log):用于记录执行时间较长的 SQL 查询语句,以帮助优化查询性能。这个阈值由配置参数 long_query_time 控制,默认值为 10 秒。若要启用慢查询日志,需要编辑 MySQL 配置文件(通常是 my.cnf 或 my.ini)并设置以下参数
slow_query_log = 1 # 启用慢查询日志,设置为 1 表示启用,0 表示禁用。 slow_query_log_file = /path/to/slow-query.log long_query_time = 1 # 设置慢查询的时间阈值,以秒为单位定期分析慢查询日志是优化数据库性能的重要步骤。我们可以汇总和分析这些日志,找出性能瓶颈,并采取相应的措施来改进查询性能。
Last modified on 2023-09-29