背景 #
在数据库概念中事务代表着一系列的操作,这些操作需要版满足ACID特性,分别是下面这些操作的首字母
-
Atomic:这些操作要么全部被commit,要么都不做;
-
Consistent: 一个事务在执行之前和执行之后,数据库都必须处于一致性状态
-
Isolatesd: 两个事务之间的操作是隔离的,当事务在执行的时候彼此看不到各自的修改,只能看到事务执行结束之后的结果;
-
Durability:事务处理的结果必须被持久化,长期存在
如果数据库只保存在一台服务器上,设计满足ACID的属性在一般的数据库书籍中都会讲到。但是在大型系统中,数据库的一张表往往保存在多个服务器上,比如银行的存款信息可能一半在A服务器,一半在B服务器,在这种情况之下设计满足ACID的分布式事务就会麻烦很多。
比如我们现在有两个事务 T1 和 T2, 其中 T1 是表示从 x 到 y 的一个转账操作,x 和 y 的值最初都是 10,并且分别保存在服务器 A 和 B 上,T2 表示一次查询操作,它们分别可以用下面这种方式执行
T1 :
BEGIN_X
add(x, 1)
add(y, -1)
END_X
T2:
BEGIN_X
t1 = get(x)
t2 = get(y)
print t1, t2
END_X
下面我们用两阶段提交的方式来设计分布式事务。
两阶段提交 #
在两阶段提交方式中有一个专门的服务器用来做事务协调器,A,B 这些服务器叫参与者(paticipants)。首先协调器会发prepare消息给参与者,判断它们能否完成后续的put操作,协调器会回复 YES/NO,分别表示下图中的①和②。当协调器发现两个服务都回复了 YES,协调器会发 commit 消息,参与者 commit 之后会回复 ACK 确认消息,只要有一个回复NO,就会发abort消息,回滚这个事务,如下图的③和④。通过这两个阶段就保证了分布式事务的一致性。
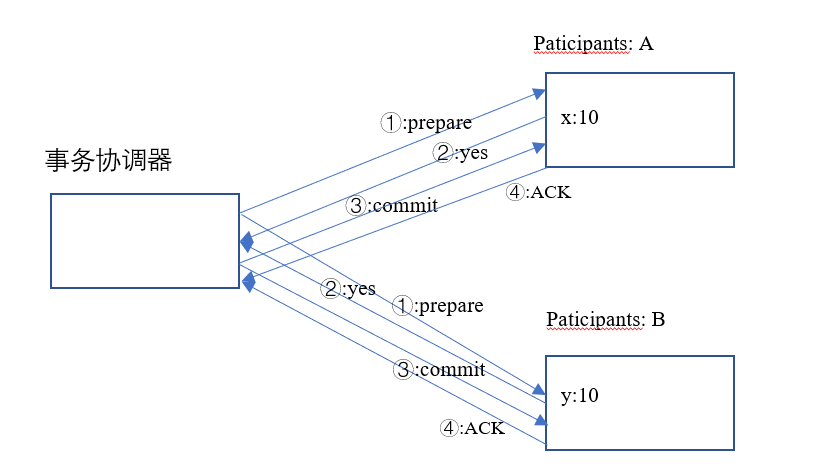
下面我们来看一下两阶段具体是怎么解决分布式系统中可能会导致不一致的各种情况的:
首先参与者可能会发生崩溃,我们不妨假设发生崩溃的就是服务器 B,B在发生中断之后就会重启,重启后一般会恢复正常。B 可能会在下面这几种情况下发生崩溃,
-
B 在回复 prepare 前中断:因为 B 不会回复协调器,协调器判断超时后会终止;
-
B在回复后中断:B 在回复 prepare 消息之前就要先获取 y 这个字段的锁,如果是数据库可能会获取一整条记录的行锁,同时会把事务在内存中管理数据的中间状态之持久化到磁盘上,防止崩溃中止。在回复YES之前已经执行了 PUT 的操作,并且持久化到磁盘。如果回复完之后崩溃,重启后B会根据日志来恢复;
-
B在收到 commit 之后崩溃,因为已经持久化过了,所以不需要做什么操作。协调器收不到ACK消息可能会多次发commit,这时等到B重启后就会回复。
协调器也有可能会崩溃,假如发完 commit 之后协调器崩溃,协调器必须把事务的 commit 状态持久化,这样在重启之后才能再次发 commit。
假如发送的消息丢包了,如果协调器等了很久都没有收到回复就会回滚事务,但是参与者在等待 commit 消息的时候收不到消息不能释放锁,只能一直等,这个行为叫阻塞。
从上面的介绍中我们不难看出两阶段提交其实存在着下面的缺点,
-
两阶段提交涉及大量的通信,速度慢
-
不能做到高可用,一旦出现故障,只能通过日志恢复
对于第二点,我们可以尝试采用 raft 集群来做协调器和参与者来提升,如下图
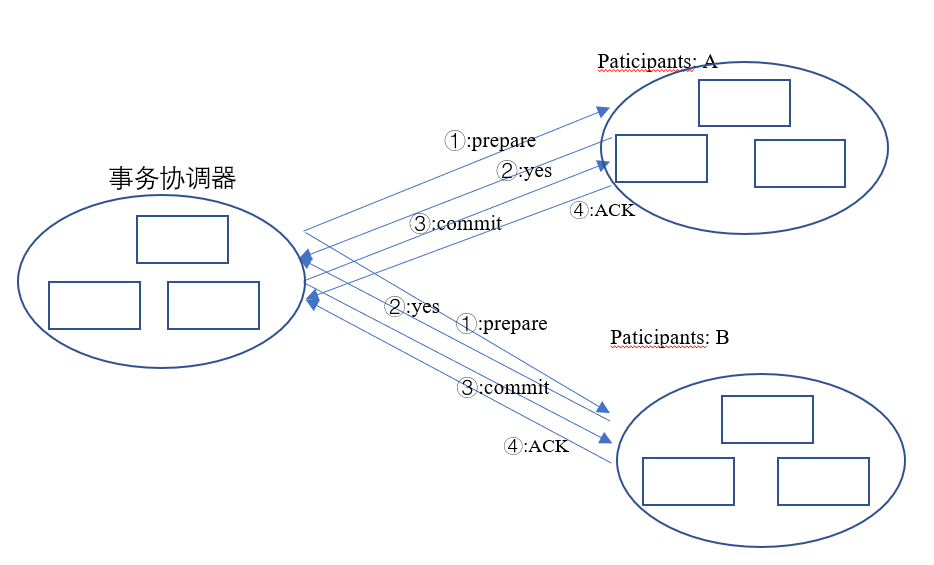
假如我们采用 raft 集群,对于每一台协调器服务器来说,它们做的事情都是一样的,并且在上图中这样一个三台服务器的集群中我们可以允许有一台服务器处于故障状态,这样就保证了分布式事务的高可用性。
Last modified on 2023-03-05