这篇博客主要记录 raft 算法添加日志条目的过程,这里用到的一些代码和思路主要来源于 MIT 6.824 课程 , 课程中提供的材料raft 论文 和 Github 上一些开源的代码实现。
raft 算法主要是以一种 lib 库的方式嵌入在应用程序中来保证分布式系统的一致性。在课程的实验中将 raft 将项目的结构划分成了下图所示这种方式。
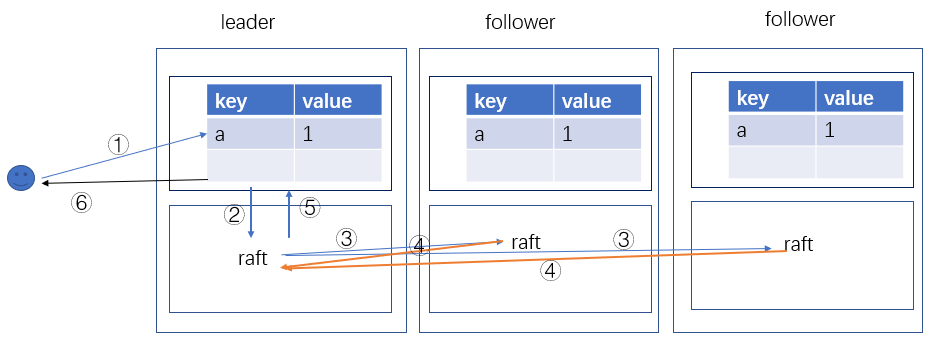
我们假设现在是一个由三台服务器组成的分布式集群(为了保证投票时“大多数”的条件永远成立,这里集群的数目必须是奇数),每台服务器的上层都维护了一个 < key, value > 的数据库,下层是 raft 算法的实现,它们通过 raft.go 里的 Start 函数做为接口进行交互。
在我们彻底弄懂上面那张图表达的意思之前让我们先来了解一下 raft 本身维护了哪些状态,下面的结构体里展示了 raft 自身的全部状态,针对这篇博客的内容,我们大概只需要了解我中文注释的这一部分就可以。这里有些状态是针对 leader 的,有些是 follower 的,有些则是它们共有的属性。分布式系统往往有成百上千台机器,而每台服务器上跑的代码都是一样的。所以当我们在编写代码的时候,必须对什么样的角色可以执行这段代码时刻保持清醒的认知。否则有些流程可能只有 leader 才会执行,如果我们没有事先检验调用者的身份,就会导致 follower 也会执行这部分代码,在一个分布式系统中这种操作导致出错的可能性是非常高的。
type Raft struct {
mu sync.Mutex // 用来保证状态一致性的锁
peers []*labrpc.ClientEnd // 保存了集群中每一台服务器的信息,在我们的例子中是3台
persister *Persister // Object to hold this peer's persisted state
me int // “我”这台服务器在 peers 中的位置
dead int32 // set by Kill()
state RaftState // Follower, Candidate, Leader 3种状态
appendEntryCh chan *Entry
heartBeat time.Duration
electionTime time.Time
// Persistent state on all servers:
currentTerm int
votedFor int
log Log
// Volatile state on all servers:
commitIndex int // 所有commit的log中的最大index
lastApplied int // 所有applied的log中最新的index
// Volatile state on leaders:
nextIndex []int // 这台服务器中保存的应该发给所有服务器的下一条log的index
matchIndex []int // 已知被复制到所有服务器上的log的最新index
applyCh chan ApplyMsg
applyCond *sync.Cond
}
可能到这里你并不知道它们到底是用来做什么的,别急,我们这就来解开这个谜题。我们还是从最开始的那张图入手,第一步就是客户端向 leader 发送请求,可能是修改 < key, value > 数据库里的某一个字段的值,然后上层就会调用 Start 函数进如 raft 流程,这也就是第②步。令人兴奋的是这两步在 6.824 的实验的代码框架里已经被实现了,我们可以直接从调用之后开始我们代码的编写。
Start 函数传递的参数就是 client 执行的这条命令 command,代码实现如下图所示
func (rf *Raft) Start(command interface{}) (int, int, bool) {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.state != Leader {
return -1, rf.currentTerm, false
}
index := rf.log.lastLog().Index + 1
term := rf.currentTerm
log := Entry{
Command: command,
Index: index,
Term: term,
}
rf.log.append(log)
rf.persist()
rf.appendEntries(false)
return index, term, true
}
我们这里还需要注意到第 4 行的代码,如果当前执行代码的服务器不是 leader 就直接返回,这更加反映了我们前面提到的任意一段代码都可能被所有的服务器执行,确定当前执行代码的角色至关重要。
接着从第 4 行往下我们发现 leader 拼凑好了 log 的内容,并且把自己的状态进行了更新,然后就执行了appendEntries 这个函数把 log 内容发给其他的服务器,参数表示是否是心跳,相当于第 ③ 步。这一步我们不去做深入,只需要了解到每台服务器都收到了来自 leader 的 AppendEntriesArgs rpc 消息,消息中包含的内容如下
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []Entry
LeaderCommit int
}
发送的过程如下
lastLog := rf.log.lastLog()
for peer, _ := range rf.peers {
if peer == rf.me {
rf.resetElectionTimer()
continue
}
if lastLog.Index >= rf.nextIndex[peer] || heartbeat {
nextIndex := rf.nextIndex[peer]
if nextIndex <= 0 {
nextIndex = 1
}
if lastLog.Index+1 < nextIndex {
nextIndex = lastLog.Index
}
prevLog := rf.log.at(nextIndex - 1)
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: prevLog.Index,
PrevLogTerm: prevLog.Term,
Entries: make([]Entry, lastLog.Index-nextIndex+1),
LeaderCommit: rf.commitIndex,
}
copy(args.Entries, rf.log.slice(nextIndex))
go rf.leaderSendEntries(peer, &args)
}
}
我们在 Start 函数里看到 leader 通过 append 添加了最新的命令到自己的 log 中,其实就是将自己的Entries数组做了更新,然后它就把自己当前的 Entries发给了其他的服务器,还包括了任期 Term, LeaderId (就是 Raft 结构体里的 me),PrevLogIndex 和 PrevLogTerm(这两个从上面的代码中很容易理解,就是 leader 认为当前状态下其他服务器中保存的最新 log 的 index 和 term),LeaderCommit(当前 commit 的最新的 index)。
关于 commit 我们这里多说一点,虽然我们已经看到 leader 把最新的 command 添加到了 log 中,但这并不代表就已经 commit 了,它需要得到大多数的服务器都把这个 command 添加到了 log 中时才会去 commit这条日志,在本文的例子中只要由一台服务器保存了这条日志就已经是大多数了,在计算的时候是要包括 leader 自己的。raft 之所以选择大多数这个条件,就是因为在一次投票中至少可以保证有一台服务器在上次投票中依然是大多数中的一员,还是用来保证集群的一致性。
为了使我们思考更加简单,这里我们直接假设另外两台服务器都成功响应并且返回了 OK。在 leader 每次收到来自 follower 的应答消息的时候 leader 会去统计一下当前已经保存日志的服务器数量,只要超过半数就会提交这条日志,这样就执行完了④和⑤这个过程。
if rf.state != Leader {
return
}
for n := rf.commitIndex + 1; n <= rf.log.lastLog().Index; n++ {
if rf.log.at(n).Term != rf.currentTerm {
continue
}
counter := 1
for serverId := 0; serverId < len(rf.peers); serverId++ {
if serverId != rf.me && rf.matchIndex[serverId] >= n {
counter++
}
if counter > len(rf.peers)/2 {
rf.commitIndex = n
rf.apply()
break
}
}
}
上面代码中 rf.commitIndex = n 对下层 raft 的 commitIndex 做了更新,rf.apply() 就是调用第⑤步的接口,然后上层就会保存到 < key, value > 数据库中。
最后就是返回给 client 应答消息,尽管这一套流程走完可能已经过了很久,但这是为了保证一致性所做的必要的牺牲。
到这里保存日志条目的流程就全部结束了,整篇博客其实都介绍了最开始的那张图,如果您已经理解了那张图表示的每一个部分,那说明您已经了解了 raft 的这个机制。
Last modified on 2023-02-11