这篇博客主要是学习MIT的公开课6.824分布式系统 的学习笔记,在课程一开始老师主要介绍了分布式系统的和MapReduce的基本概念,后续有关于实现一个具体的MapReduce的实验。
MapReduce #
MapReduce是谷歌大数据三驾马车中的其中一篇论文,它被提出的目的是用来解决海量网页数据索引和排序之类的问题。它包含Map和Reduce两个过程,以WordCount为例,它的计算过程如下图所示:
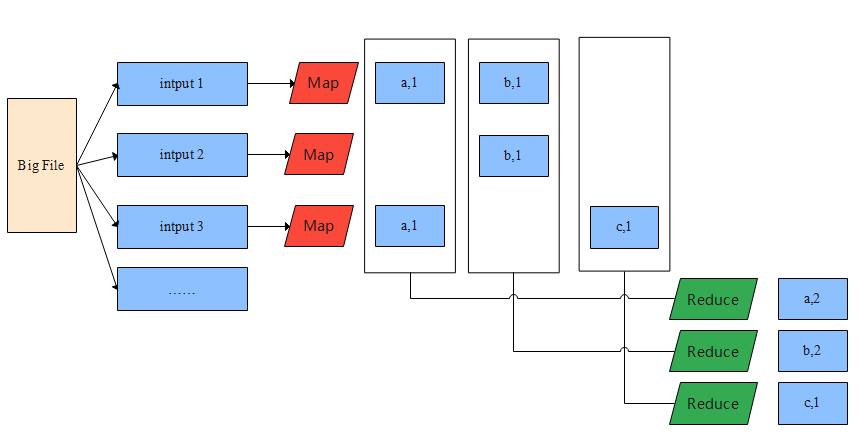
当我们面临着一个大文件的时候,谷歌的文件系统GFS(Google File System)会把它差分成多个64kb的块,用来做任务分配的master服务器知道它们具体在哪台机器上,然后它会指定work machine去执行Map的操作。加入这些文件块的存放位置和work machine不是同一台机器,那就需要通过网络通信来进行数据交换,可是这样会导致效率下降,所以一般都会将它们放在同一台机器上,work machine只需要做一个文件读取的操作就可以了。Map(k,v)的v指的就是某一个块的全部文字,所以下面只需要将单词拆分开然后变成key,1的形式就可以了。

图片来源:Google MapReduce论文
在整个Map的过程中master是不需要去一致盯着每台机器去做运算的,每个work machine会将自己运算的中间结果保存在自己的本地磁盘上。以上图中的INPUT 1为例,它最终会保存(a,1)和(b,1)两个值。
然后是Reduce的过程,MapReduce worker通过网络收集所有完成了map worker中<key(i), 1>的任务task,从存储在各个Map worker磁盘上收集数据。这里并不要求每一个Map的所有任务都完成,如果只请求(a,1)这个Map过程,只要work machine完成了这一个任务,就可以将结果返回,不用等全部工作完成。Reduce的伪代码可以表示如下:

图片来源:Google MapReduce论文
它的实现相对简单一点,只是对这些收集到的信息做一个加总的操作,计算出长度就行了。
Last modified on 2022-04-20